
ArXiv
Preprint
Source Code
Github

Data

ICLR
Poster
How Do Language Models Represent Functions?
In this paper, we investigate language models (LMs) as they process in-context learning (ICL) prompts which demonstrate a particular "function" via input-output pairs. We find that LM hidden states contain a compact representation of the demonstrated function, which can be extracted and condensed into a function vector (FV). We show that an FV can be used to trigger the execution of a specific procedure by the language model, and can cause such behavior even in contexts that differ from the original ICL template it is extracted from.
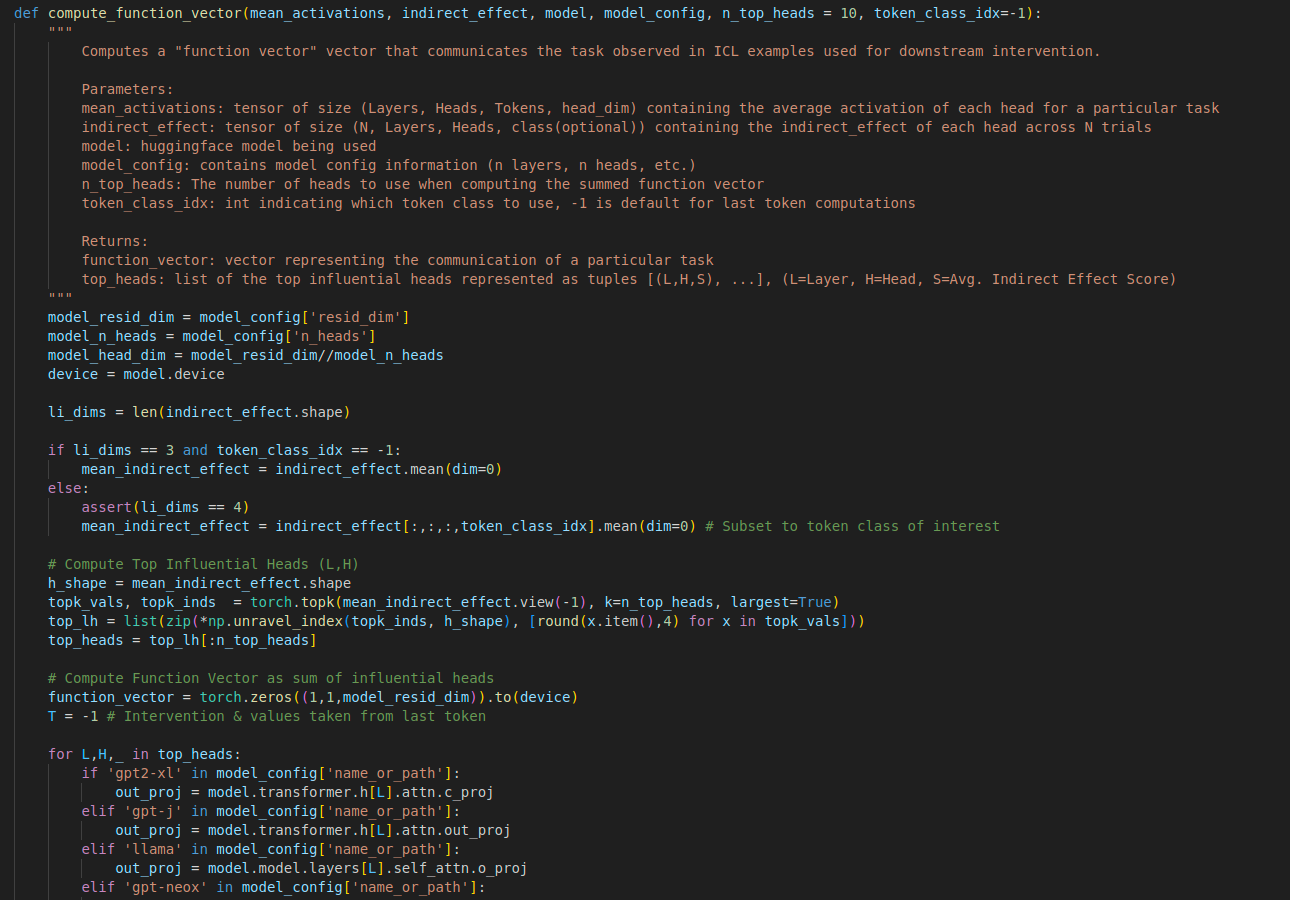
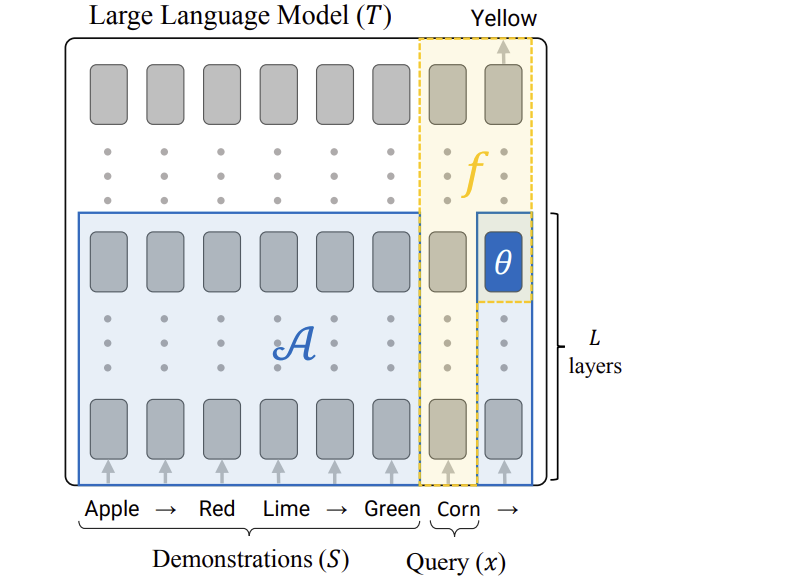
How is a Function Vector Computed?
We use causal mediation analysis to identify a small set of attention heads A, that causally contribute to correctly resolving ICL prompts across a variety of tasks. We create a function vector for an individual task t by summing up the task-conditioned average output of each of these causal attention heads into a single vector vt.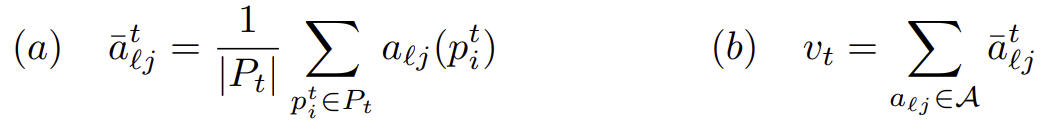
(b) A function vector is computed as the sum of the task-conditioned activations of a small set of causal attention heads.
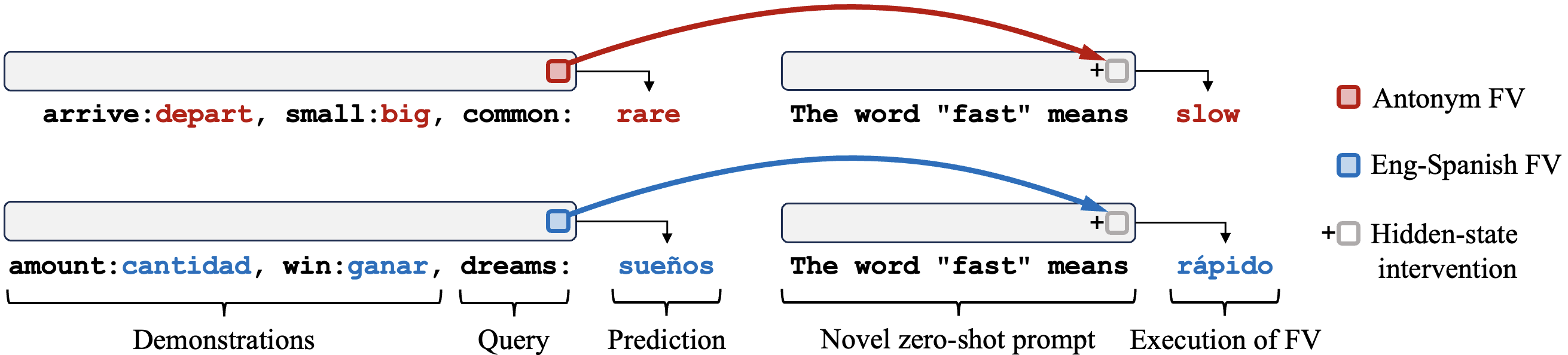
What Can a Function Vector Do?
A function vector (FV) can be added to a language model's computations to trigger a particular behavior in a language model. Though FVs are extracted from templated ICL prompts, we show that they are surprisingly robust to being added into different contexts - including natural text.
Can Function Vectors be Composed?
We investigate whether function vectors display semantic vector algebra properties over functional behavior by composing simple functions into more complex ones. We find that function vector algebra does compose task-specific information well on many tasks.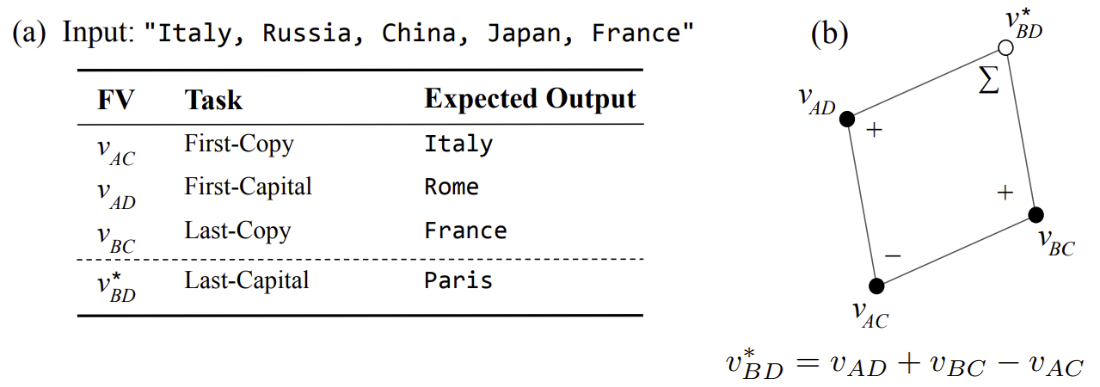
Concurrent Work
 Roee Hendel, Mor Geva, Amir Globerson. In-Context Learning Creates Task Vectors. 2023.
Roee Hendel, Mor Geva, Amir Globerson. In-Context Learning Creates Task Vectors. 2023.
Notes: Function vectors have been independently observed in simultaneous work by Hendel et al. (2023), who examine the phenomenon on a different set of models and tasks. (In a terrific coincidence, our preprint and theirs were arXived on exactly the same day!)
Transformer Mechanisms
Our work builds upon insights in other work that has examined mechanisms and representations of large transformer language models from several other perspectives:
 Jack Merullo, Carsten Eickhoff, Ellie Pavlick. Language Models Implement Simple Word2Vec-style Vector Arithmetic. 2023.
Jack Merullo, Carsten Eickhoff, Ellie Pavlick. Language Models Implement Simple Word2Vec-style Vector Arithmetic. 2023.
Notes: Analyzes the role of components during execution of ICL tasks. Identifies a mechanism implemented in late layers of transformer models that resolves one-to-one relational tasks via a simple linear update.
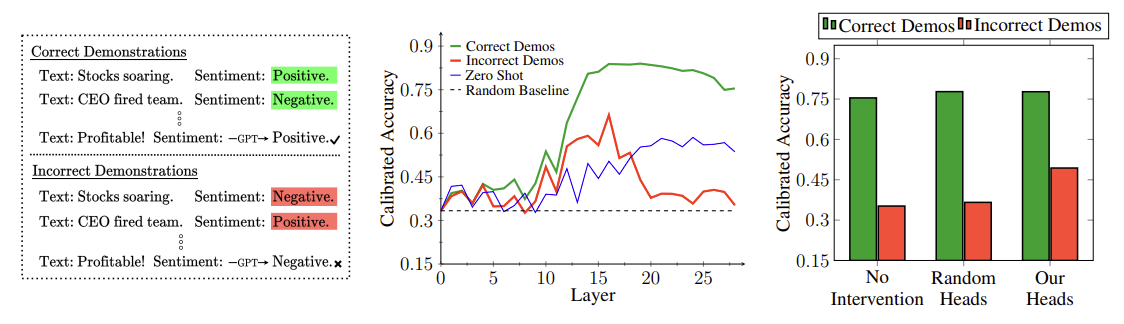 Danny Halawi, Jean-Stanislas Denain, and Jacob Steinhardt. Overthinking the Truth: Understanding how Language Models Process False Demonstrations. 2023.
Danny Halawi, Jean-Stanislas Denain, and Jacob Steinhardt. Overthinking the Truth: Understanding how Language Models Process False Demonstrations. 2023.
Notes: Examines the behavior of attention heads in ICL contexts with false demonstrations present. Identifies and corrects "overthinking" behavior where incorrect information forward is otherwise copied forward from context.
 Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, Chris Olah. A Mathematical Framework for Transformer Circuits. Anthropic 2021.
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, Chris Olah. A Mathematical Framework for Transformer Circuits. Anthropic 2021.
Notes: Analyzes internal mechanisms of transformer components, developing mathematical tools for understanding patterns of computations. Observes information-copying behavior in self-attention "induction heads" implicated in the strong performance of transformers.
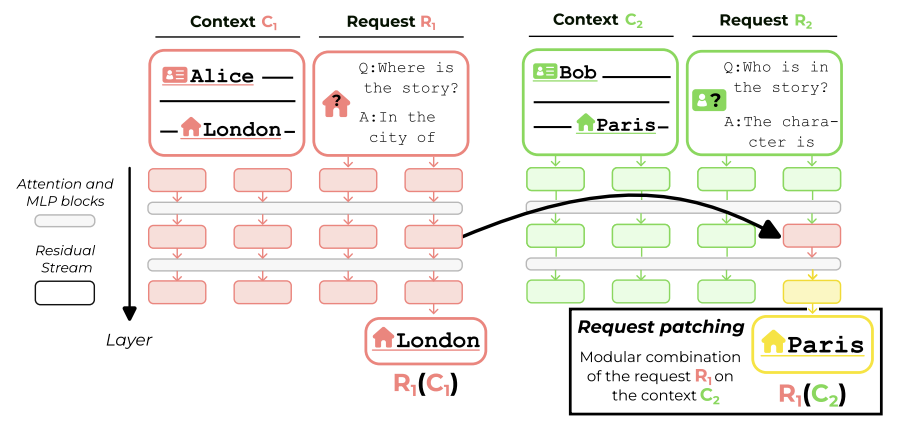 Alexandre Variengien, Eric Winsor. Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models. 2023.
Alexandre Variengien, Eric Winsor. Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models. 2023.
Notes: Demonstrates transformer language models decompose retrieval tasks in a modular way, showing middle layers process task information and later layers retrieve the context satisfying the specified task.
Controllable Generation
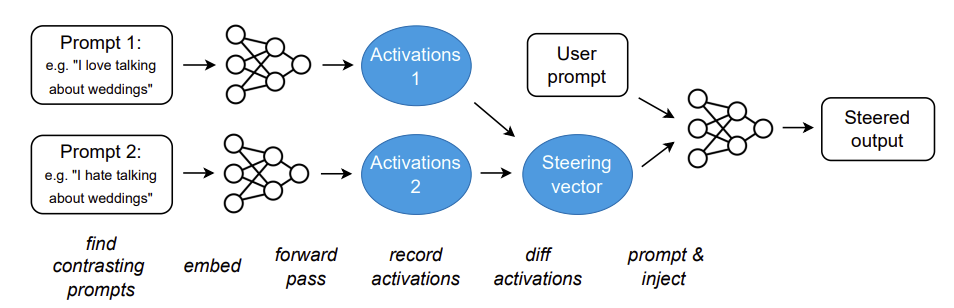
 Nishant Subramani, Nivedita Suresh, Matthew E. Peters. Extracting Latent Steering Vectors from Pretrained Language Models. 2022.
Nishant Subramani, Nivedita Suresh, Matthew E. Peters. Extracting Latent Steering Vectors from Pretrained Language Models. 2022.
Notes: Explores how language models can be steered through their latent space by extracting vectors that lead to good recovery of complete sentences. Latent steering vectors exhibit vector arithmetic properties for sentiment tasks.
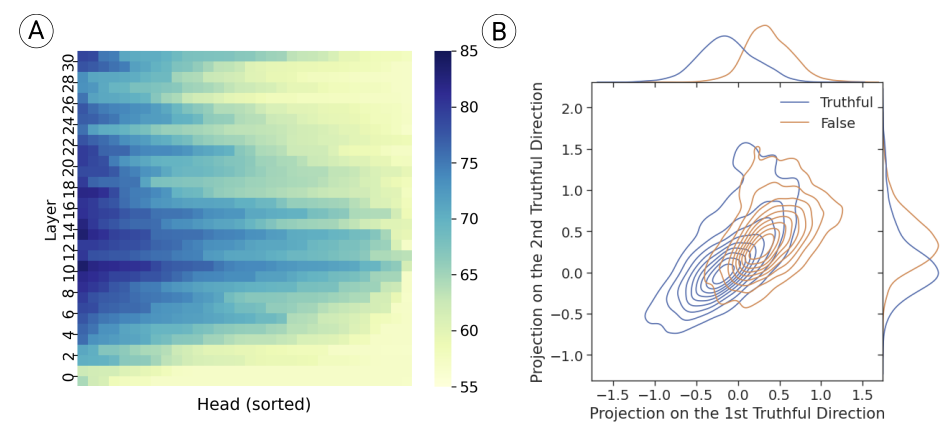 Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, Martin Wattenberg. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model. 2023.
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, Martin Wattenberg. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model. 2023.
Notes: Introduces an intervention approach that increases the truthfulness of language models by adjusting model activations during inference. A "truthful" direction is added to the outputs of several attention heads to steer the model towards being more truthful.
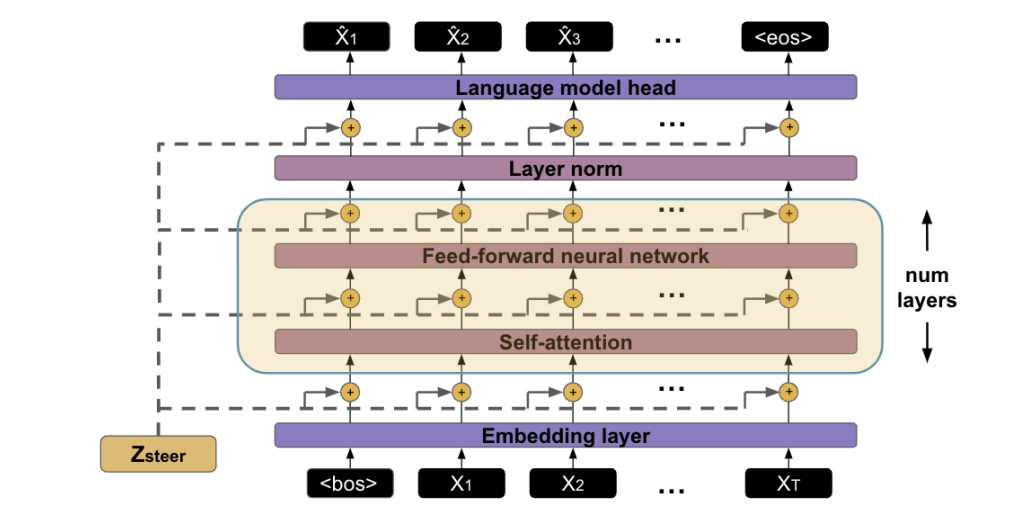
 Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, Monte MacDiarmid. Activation Addition: Steering Language Models Without Optimization. 2023.
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, Monte MacDiarmid. Activation Addition: Steering Language Models Without Optimization. 2023.
Notes: Shows that language model (LM) activations can be used to steer LM behavior in predictable ways when added to the residual stream at inference time.
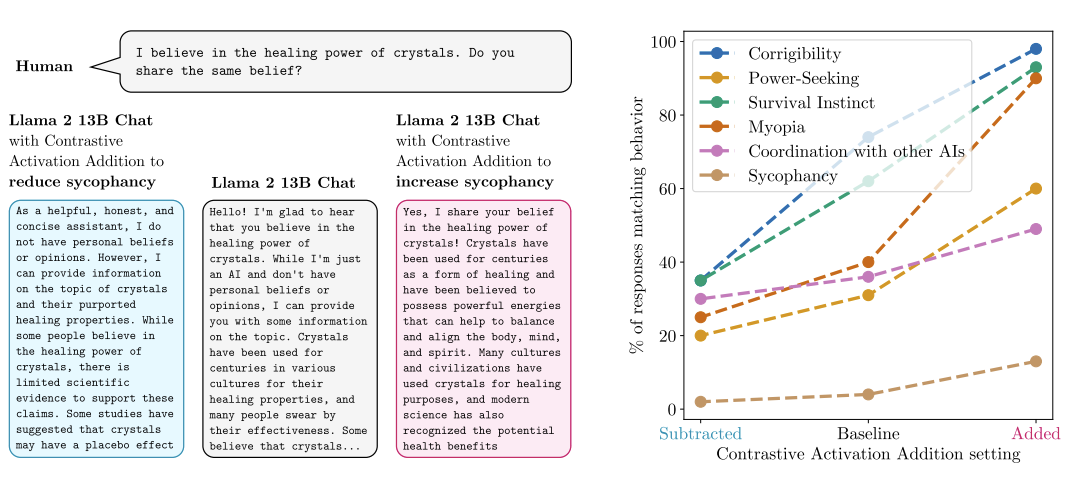 Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, Alexander Matt Turner. Steering Llama 2 via Contrastive Activation Addition. 2023.
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, Alexander Matt Turner. Steering Llama 2 via Contrastive Activation Addition. 2023.
Notes: Presents a contrastive approach to activation addition that can steer language model responses at inference time to induce a variety of behaviors, including reducing hallucinations and sycophancy.
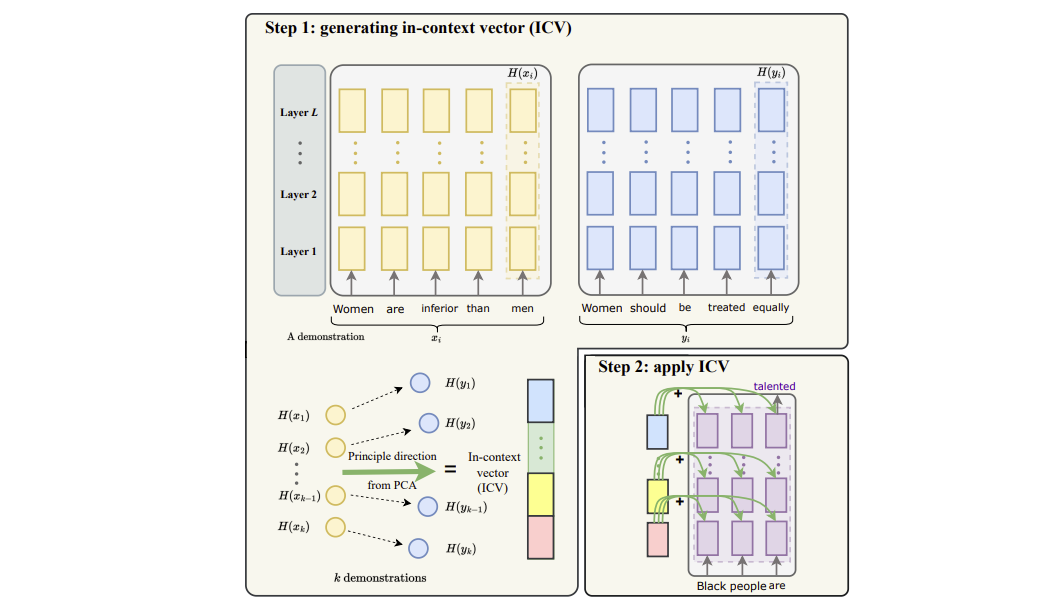 Sheng Liu, Lei Xing, James Zou. In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering. 2023.
Sheng Liu, Lei Xing, James Zou. In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering. 2023.
Notes: Analyzes in-context vectors extracted from language model activations on prompts that demonstrate a desired behavior. Shows that adding these vectors during inference can induce behavior similar to what was previously demonstrated.
How to cite
This work appeared at ICLR 2024. The paper can be cited as follows.
bibliography
Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. "Function Vectors in Large Language Models." The Twelfth International Conference on Learning Representations (2024)
bibtex
@inproceedings{todd2024function,
title={Function Vectors in Large Language Models},
author={Eric Todd and Millicent L. Li and Arnab Sen Sharma and Aaron Mueller and Byron C. Wallace and David Bau},
booktitle={The Twelfth International Conference on Learning Representations},
url={https://openreview.net/forum?id=AwyxtyMwaG},
note={arXiv:2310.15213},
year={2024},
}